
모든 PDF가 똑같이 만들어진 것은 아닙니다. 어떤 PDF는 텍스트를 자유롭게 복사할 수 있는 반면, 어떤 PDF는 이를 완전히 막아 둡니다. 텍스트를 선택하고 복사하려는 시도가 통하지 않는다면, 스캔된 문서이거나 복사 제한이 설정된 파일일 가능성이 있습니다.
다행히 스캔된 PDF에서 텍스트를 복사하는 효과적인 방법은 여러 가지가 있으며, 잠겨 있거나 편집 가능한 텍스트 대신 스캔된 페이지가 포함된 경우에도 가능합니다. 이 가이드에서는 다양한 해결책을 단계별로 안내하여 PDF 안의 텍스트에 자유롭게 접근하고 재사용하며 활용할 수 있도록 도와드립니다.
PDF 파일에서 텍스트를 복사할 수 있나요?
네, 대부분의 경우 스캔된 이미지가 아닌 디지털로 임베디드된 텍스트가 포함된 PDF에서는 내용을 복사할 수 있습니다. 디지털로 임베디드된 텍스트란 이미지의 일부가 아니라 실제 텍스트 데이터로 저장된 문자를 의미하며, 표준 단축키를 사용해 내용을 선택하고 복사하여 붙여넣을 수 있도록 해 줍니다.
일반 PDF에서 텍스트를 복사하는 방법은 다음과 같습니다:
- 1사용 중인 기기의 PDF 리더에서 PDF를 엽니다(예: Windows의 Microsoft Edge 또는 Mac의 Preview).
- 2필요한 텍스트를 선택하거나, Ctrl+A(Windows) 또는 Cmd+A(macOS)를 눌러 전체를 선택합니다.
- 3Ctrl+C/Cmd+C를 눌러 복사합니다.
- 4텍스트를 넣고자 하는 대상 문서를 열거나 새로 만듭니다.
- 5Ctrl+V/Cmd+V를 눌러 텍스트를 붙여넣기합니다.
모든 단계가 정상적으로 작동했다면 복사한 내용이 클립보드에 저장되어 어떤 문서나 앱에도 붙여넣을 준비가 된 상태입니다.
PDF Guru의 OCR 도구로 PDF에서 텍스트를 복사하는 방법
PDF가 스캔된 파일이거나 이미지로만 구성된 문서라면, 텍스트가 선택 가능한 형태로 저장되어 있지 않기 때문에 직접 복사할 수 없습니다. 내용을 사용할 수 있도록 만들려면 AI 기반 광학 문자 인식(OCR)을 적용해야 하며, AI 기술은 이미지를 분석하여 선택, 검색, 편집이 가능한 텍스트로 변환합니다.
PDF Guru의 OCR 변환기 사용 방법으로 PDF나 이미지에서 텍스트를 추출하는 절차는 다음과 같습니다:
- 1파일을 업로드하거나 끌어다 놓습니다.
- 2
출력 형식을 선택합니다: 검색 가능한 PDF, Word 문서, 또는 일반 텍스트.
- 검색 가능한 PDF는 레이아웃과 디자인을 그대로 유지합니다.
- Word는 추가 편집에 가장 적합합니다.
- 일반 텍스트는 어떠한 서식도 없이 원본 콘텐츠만 제공합니다.
- 3
다운로드를 클릭하고 시스템이 파일을 처리하는 동안 잠시 기다리세요.
바로 편집으로 넘어가고 싶으신가요? PDF를 Word로 변환기를 사용해 보세요.

PDF가 텍스트 복사를 허용하는지 어떻게 확인하나요?
PDF에서 텍스트를 복사하고 붙여넣을 수 없다면, 보통 두 가지 문제 중 하나로 귀결됩니다: 파일이 스캔된 형태이거나(즉, 텍스트가 이미지의 일부), 복사를 막는 보안 제한이 걸려 있는 경우입니다. 문제의 원인을 파악하는 방법은 다음과 같습니다.
1단계: 텍스트 선택 시도하기
PDF 문서에서 어떤 텍스트도 선택할 수 없다면, 스캔된 이미지가 포함되어 있을 가능성이 큽니다. 이 경우 저희 PDF to OCR 변환기를 사용해 보세요. 이 도구는 스캔본을 검색 가능하고 편집 가능한 파일로 변환해 줍니다. 다음 섹션에서 작동 방식을 설명하겠습니다.
PDF 파일에서 텍스트는 선택할 수 있지만 복사해도 아무 일도 일어나지 않는다면, 파일에 보안 제한이 걸려 있다는 뜻입니다.
2단계: 문서 권한 확인하기
기본 PDF 리더에서 보안 설정을 확인하여 파일이 복사를 허용하는지 확인할 수 있습니다:
Windows에서:
- 1Microsoft Edge 브라우저에서 PDF를 엽니다.
- 2파일이 보호되어 있다면, Edge는 "이 파일은 권한이 제한되어 있습니다. 일부 기능을 사용하지 못할 수 있습니다"와 같은 메시지를 표시하며, 도구 모음 아래에 "권한 보기" 링크가 함께 나타나는 경우가 많습니다.
- 3제한 사항에 대해 알아보려면 (사용 가능한 경우) "권한 보기"를 클릭하세요. 여기에는 복사, 인쇄, 주석 추가가 가능한지 여부가 포함될 수 있습니다. 그러나 Edge는 모든 권한 설정에 대한 전체 내역을 제공하지는 않습니다.
- 4복사가 제한된 경우 복사할 수 없는 PDF에서 텍스트를 복사하려는 시도는 실패합니다. Edge는 별다른 안내 없이 작업을 차단합니다.
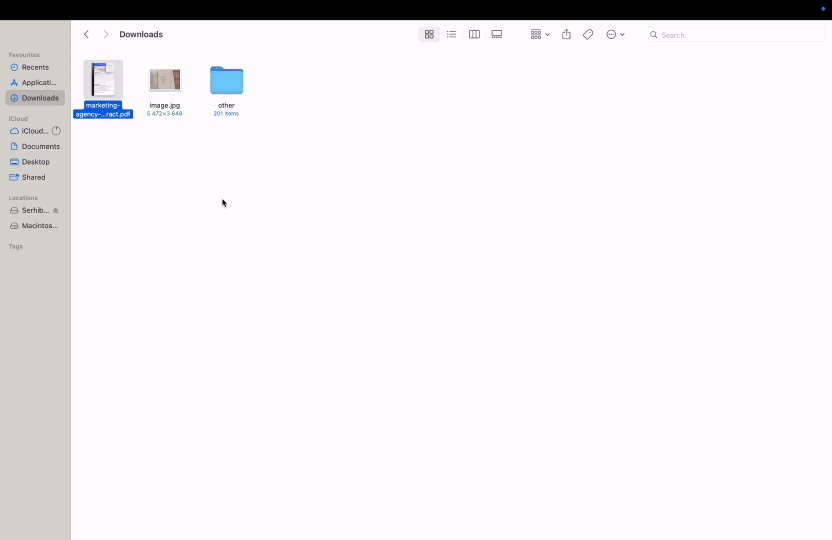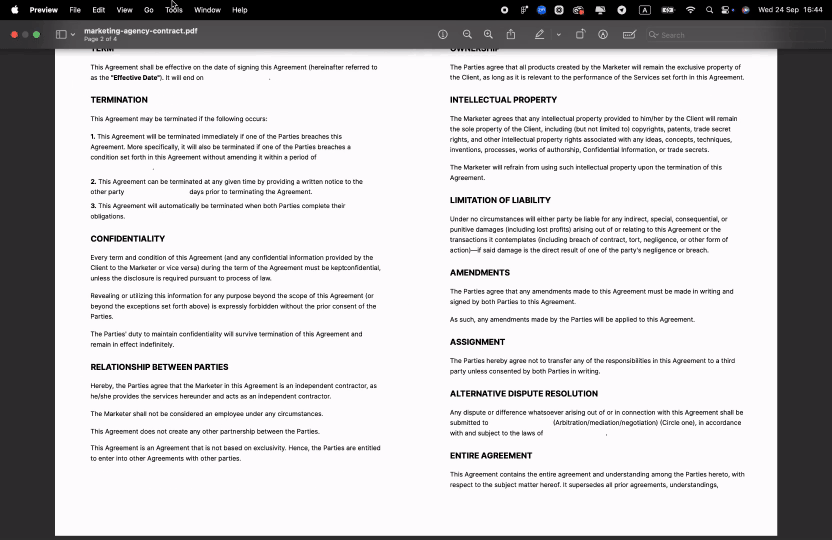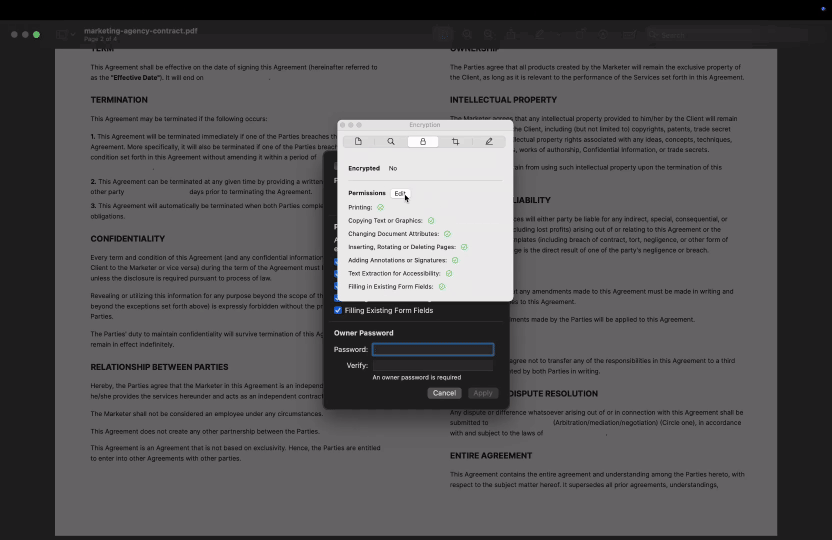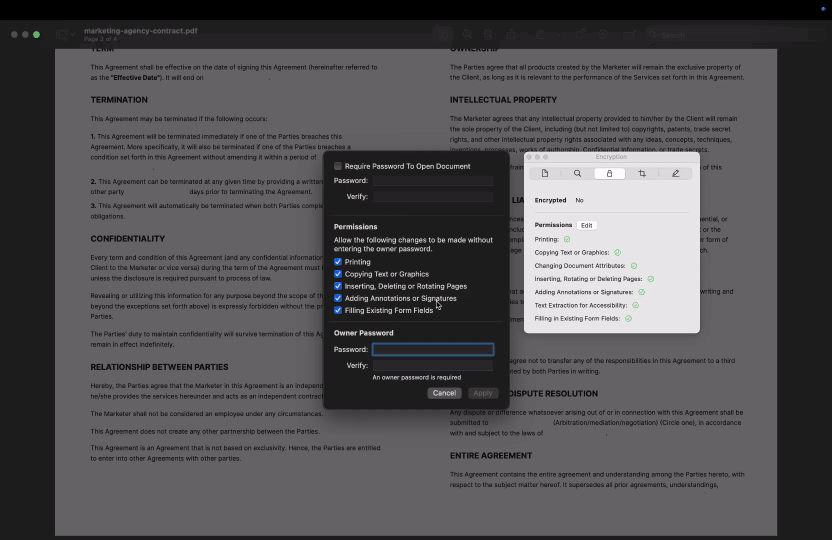
macOS에서:
- 1Preview에서 PDF를 엽니다.
- 2비밀번호로 보호된 PDF의 경우 도구 > 검사기 표시를 클릭한 다음 암호화 탭을 선택해 복사나 인쇄 등 권한이 제한되어 있는지 확인할 수 있습니다.
- 3Preview는 비밀번호로 보호되지 않은 파일에 대해서는 상세한 권한 정보를 표시하지 않습니다. 복사가 제한되어 있다면 프로그램은 별다른 설명 없이 텍스트 복사를 차단합니다.
PDF 텍스트가 복사 제한되어 있을 때 해결 방법
텍스트 복사가 제한되어 있지만 비밀번호를 알고 있다면, 파일을 잠금 해제하여 이러한 제한을 풀 수 있습니다. 이러한 형태의 비밀번호 보호는 사용자가 복사뿐만 아니라 PDF 파일을 편집할 수 없는 흔한 이유이기도 합니다.
보호된 PDF에서 텍스트를 복사하는 방법
PDF에 복사 제한이 걸려 있다면 문서 소유자에게서 받은 올바른 비밀번호를 입력하세요. 잠금이 해제되면 텍스트를 선택하고 복사할 수 있습니다.
저희 OCR 도구는 암호화된 문서에 대한 개인정보 및 법적 보호를 존중하기 때문에 비밀번호로 보호된 파일은 처리하지 않습니다. 이러한 파일을 업로드하면 "파일이 비밀번호로 보호되어 있습니다. 파일의 잠금을 해제한 후 다시 시도해 주세요"라는 메시지가 표시됩니다. 즉, 사용자가 직접 비밀번호를 제거해야 합니다. PDF 리더에서 비밀번호를 입력하거나, 변환을 실행하기 전에 파일 소유자에게 잠금 해제된 사본을 요청하세요.
법적 및 윤리적 주의 사항: 텍스트는 권한이 있거나 법적 권리가 있을 때만 복사하세요. 복사 보호를 우회하지 마세요. 저작권, 라이선스, 계약, 개인정보 규정을 준수하세요. 이는 일반적인 정보이며 법률 자문이 아닙니다.
PDF 이미지에서 텍스트를 복사하는 방법
PDF가 단순히 이미지일 뿐이라면, 스캔된 PDF와 같은 범주에 해당합니다: 복사할 수 있는 실제 텍스트 계층이 존재하지 않습니다. 해결책 역시 동일합니다 — OCR을 사용해 텍스트를 선택 가능하게 만드세요. 저희 이미지 텍스트 추출 변환기는 사진 및 이미지로만 된 PDF를 위해 제작되었으며, 사진을 스캔하고 문자를 재구성하여 선택, 검색, 재사용이 가능하도록 해 줍니다.
OCR 도구로 PDF 이미지에서 텍스트 추출하는 방법
PDF 이미지에서 텍스트를 추출하려면 저희 OCR 이미지 변환기를 사용하세요. 스캔되거나 이미지 기반의 PDF를 업로드하고 OCR 처리를 시작하면, 도구가 이미지를 기계가 읽을 수 있는 텍스트로 변환해 줍니다. 그런 다음 결과를 검색 가능한 PDF로 저장해 레이아웃을 유지하거나, 편집을 위해 Word로 내보내거나, 빠른 재사용을 위해 일반 텍스트를 복사할 수 있습니다.
Google Drive로 PDF 이미지에서 텍스트를 선택하는 방법
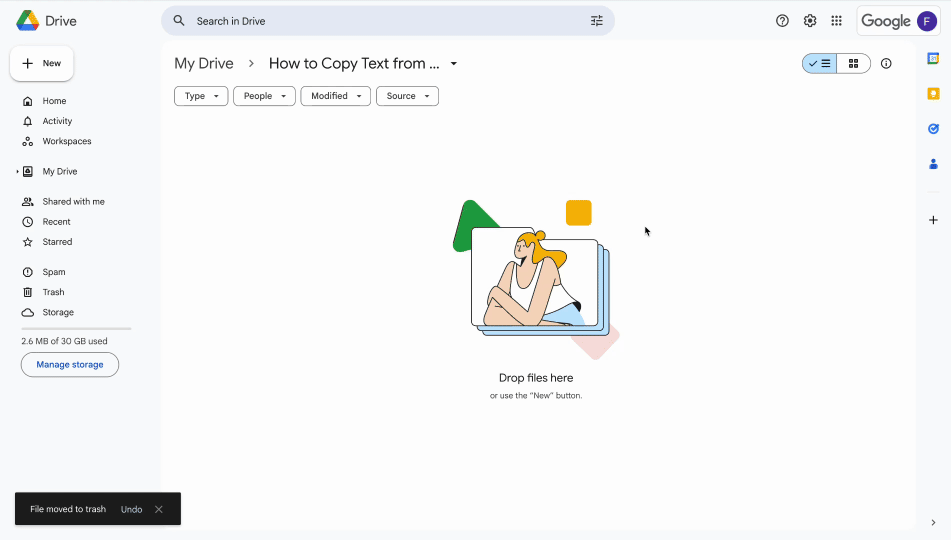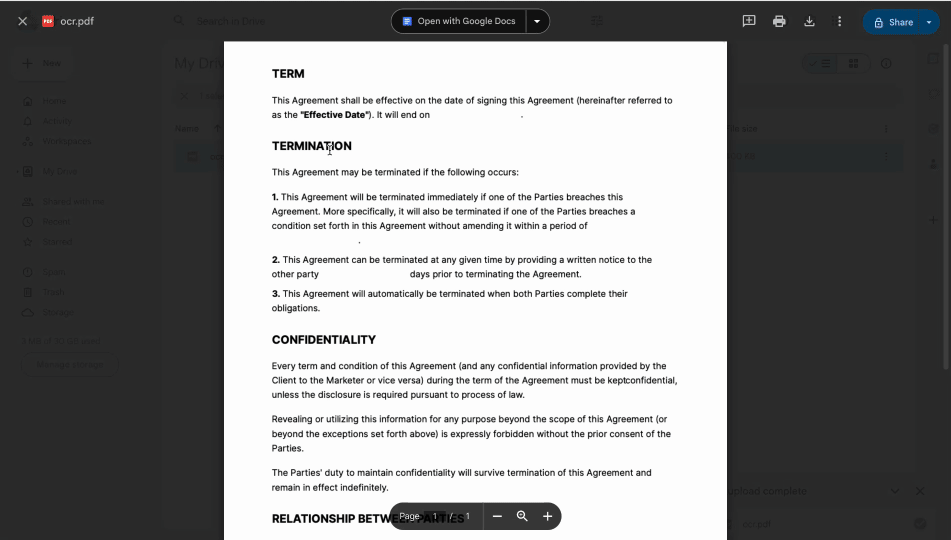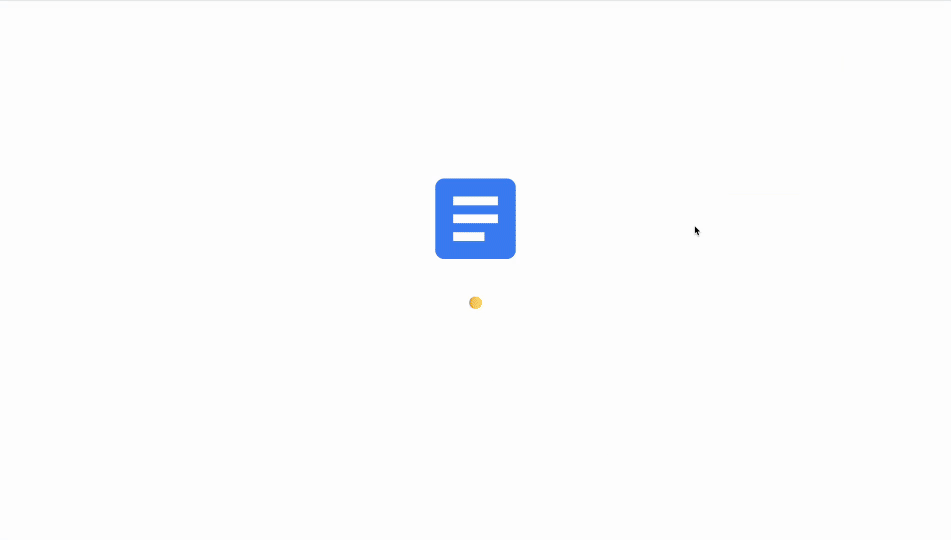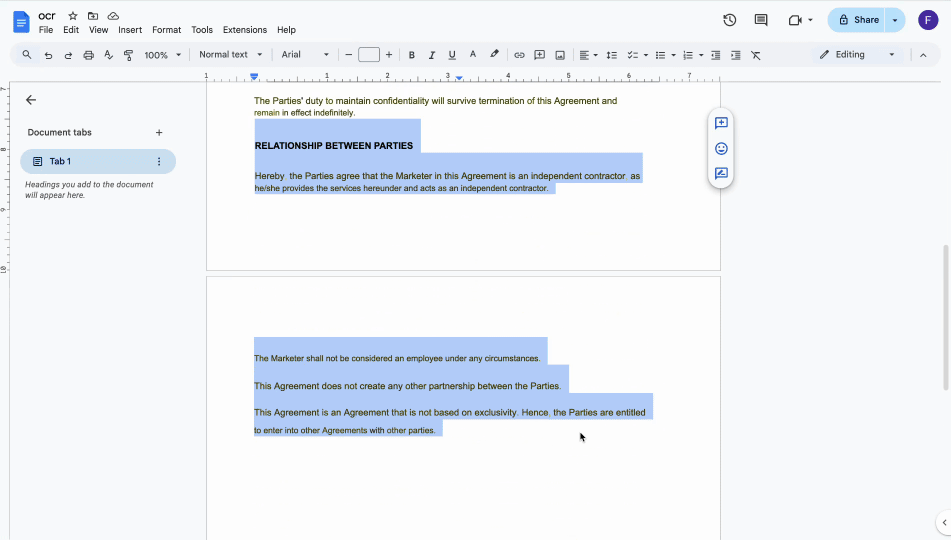
PDF 이미지에서 텍스트를 복사하려면 Google Drive에 내장된 OCR 기능을 사용할 수 있습니다. 이 기능은 이미지 기반 텍스트를 손쉽게 복사할 수 있는 기계 판독 가능한 텍스트로 자동 변환해 줍니다. 작동 방식은 다음과 같습니다:
- 1Google Drive 계정을 엽니다.
- 2PDF를 업로드합니다(새로 만들기 > 파일 업로드 또는 끌어다 놓기).
- 3업로드된 파일을 마우스 오른쪽 버튼으로 클릭하고 연결 앱 > Google Docs를 선택합니다.
PDF가 새 탭에서 Google Docs 파일로 열립니다. 이전에는 선택할 수 없었던 텍스트가 편집 가능하고 기계 판독 가능한 형태가 되어 필요한 만큼 복사하고 붙여넣을 수 있게 됩니다.
참고: 변환 과정에서 일부 서식이 손실될 수 있습니다. Google Drive는 일반적으로 굵게, 기울임 스타일, 줄 바꿈, 글꼴은 유지하지만 목록, 표, 각주 또는 기타 복잡한 요소는 유지하지 못할 수 있습니다. 서식 문제 없이 더 빠르고 일관된 결과를 원한다면, 대신 저희 PDF 편집 도구를 사용해 보세요.
OCR 최상의 결과를 위한 팁
OCR은 때때로 답답할 수 있으며, 깨끗한 스캔에서도 작은 오류가 발생할 수 있습니다. 예를 들어, 문자 "O"가 0으로 잘못 인식되거나 "rn"이 "m"으로 읽힐 수 있습니다. 정확도를 높이고 이러한 문제를 해결하는 방법은 다음과 같습니다:
- 도구가 문자를 명확히 인식할 수 있도록 텍스트가 충분히 큰지(최소 10~12픽셀 높이) 확인하세요.
- 업로드가 느려지거나 오류가 발생하지 않도록 파일 크기를 적절히 유지하세요(웹 도구의 경우 약 100MB 이하).
- 방향을 확인하세요. OCR을 실행하기 전에 거꾸로 되어 있거나 옆으로 누운 페이지를 회전시키세요.
- Arial이나 Times New Roman 같은 단순하고 읽기 쉬운 글꼴로 선명하고 대비가 높은 스캔을 목표로 하세요.
- OCR 후에는 l/1, O/0, rn/m 같은 흔한 오인식을 발견하고 수정할 수 있도록 교정하세요.
- 오류가 계속되면 더 쉬운 편집을 위해 Word나 Excel로 내보내거나 AI 기반 OCR 도구를 사용해 보세요.
이러한 방법은 Google Drive, PDF Guru 또는 기타 유사한 도구에 통합된 OCR 서비스 대부분에 적용됩니다.
PDF Guru로 스캔본을 더 스마트하게 처리하세요
스캔되거나 보호된 PDF가 더는 발목을 잡지 않아도 됩니다. OCR을 실행하면 숨겨진 텍스트를 드러내고, PDF에서 모든 텍스트를 복사하거나, 페이지를 편집 가능한 파일로 만들 수 있습니다. 올바른 도구만 있으면 잠긴 문서나 이미지로만 된 문서도 손쉽게 작업할 수 있습니다.


