
Niet alle PDF's zijn gelijk. Sommige laten je vrij tekst kopiëren, terwijl andere dat volledig blokkeren. Als je pogingen om tekst te selecteren en te kopiëren mislukken, heb je waarschijnlijk te maken met een gescand document of een bestand waarvoor kopieerbeperkingen zijn ingesteld.
Het goede nieuws is dat er verschillende effectieve methoden bestaan om tekst uit een gescande PDF te kopiëren, zelfs als het bestand vergrendeld is of gescande pagina's bevat in plaats van bewerkbare tekst. In deze gids laten we je verschillende oplossingen zien waarmee je de tekst in je PDF's vrij kunt benaderen, hergebruiken en opnieuw kunt inzetten.
Kun je tekst uit een PDF-bestand kopiëren?
Ja, in de meeste gevallen kun je inhoud kopiëren uit een PDF die digitaal ingebedde tekst bevat in plaats van gescande afbeeldingen. Digitaal ingebedde tekst betekent dat de tekens als echte tekstgegevens zijn opgeslagen, niet als onderdeel van een afbeelding. Daardoor kun je de inhoud selecteren, kopiëren en plakken met de standaard sneltoetsen, of het nu in een desktopprogramma of rechtstreeks in je browser is.
Zo kopieer je tekst uit een standaard PDF:
- 1Open je PDF in een willekeurige PDF-lezer op je apparaat (bijvoorbeeld Microsoft Edge op Windows of Preview op Mac).
- 2Selecteer de tekst die je nodig hebt (of druk op Ctrl+A (op Windows) of Cmd+A (op macOS) om alles te selecteren).
- 3Druk op Ctrl+C/Cmd+C om te kopiëren.
- 4Open of maak het doeldocument waarin je de tekst wilt invoegen.
- 5Druk op Ctrl+V/Cmd+V om de tekst te plakken.
Als alles goed werkt, staat de gekopieerde inhoud nu op je klembord, klaar om te plakken in een document of app.
Tekst uit een PDF kopiëren met de OCR-tool van PDF Guru
Als je PDF een gescand bestand is of een document dat alleen uit afbeeldingen bestaat, kun je de tekst niet rechtstreeks kopiëren, omdat deze niet als selecteerbare tekst is opgeslagen. Om de inhoud toegankelijk te maken, moet je optical character recognition (OCR) toepassen. Die analyseert de afbeelding met behulp van AI en zet die om in selecteerbare, doorzoekbare en bewerkbare tekst.
Zo gebruik je de PDF-OCR-converter van PDF Guru om tekst uit een PDF of afbeelding te halen:
- 1Upload je bestand of sleep het naar het venster.
- 2
Kies het uitvoerformaat: doorzoekbare PDF, Word-document of platte tekst.
-- Doorzoekbare PDF's behouden de lay-out en het ontwerp. -- Word is het meest geschikt voor verdere bewerking. -- Platte tekst geeft je alleen de ruwe inhoud zonder opmaak. - 3
Klik op Downloaden en wacht tot ons systeem je bestand heeft verwerkt.
Wil je meteen aan de slag met bewerken? Probeer onze PDF-naar-Word-converter.

Hoe controleer ik of een PDF kopiëren van tekst toestaat?
Als je geen tekst uit een PDF kunt kopiëren en plakken, ligt dat meestal aan een van twee oorzaken: het bestand is gescand (de tekst maakt deel uit van een afbeelding) of er gelden beveiligingsbeperkingen die kopiëren blokkeren. Zo achterhaal je de oorzaak.
Stap 1: Probeer de tekst te selecteren
Als je geen tekst in je PDF-document kunt selecteren, bevat het waarschijnlijk gescande afbeeldingen. Probeer in dat geval onze PDF-naar-OCR-converter, die deze scans omzet in doorzoekbare en bewerkbare bestanden. In het volgende deel leggen we uit hoe dat werkt.
Als je wel tekst in PDF-bestanden kunt selecteren maar er gebeurt niets wanneer je kopieert, betekent dat dat het bestand beveiligingsbeperkingen heeft.
Stap 2: Controleer de documentmachtigingen
Je kunt controleren of je bestand kopiëren toestaat door de beveiligingsinstellingen na te kijken in je standaard PDF-lezer:
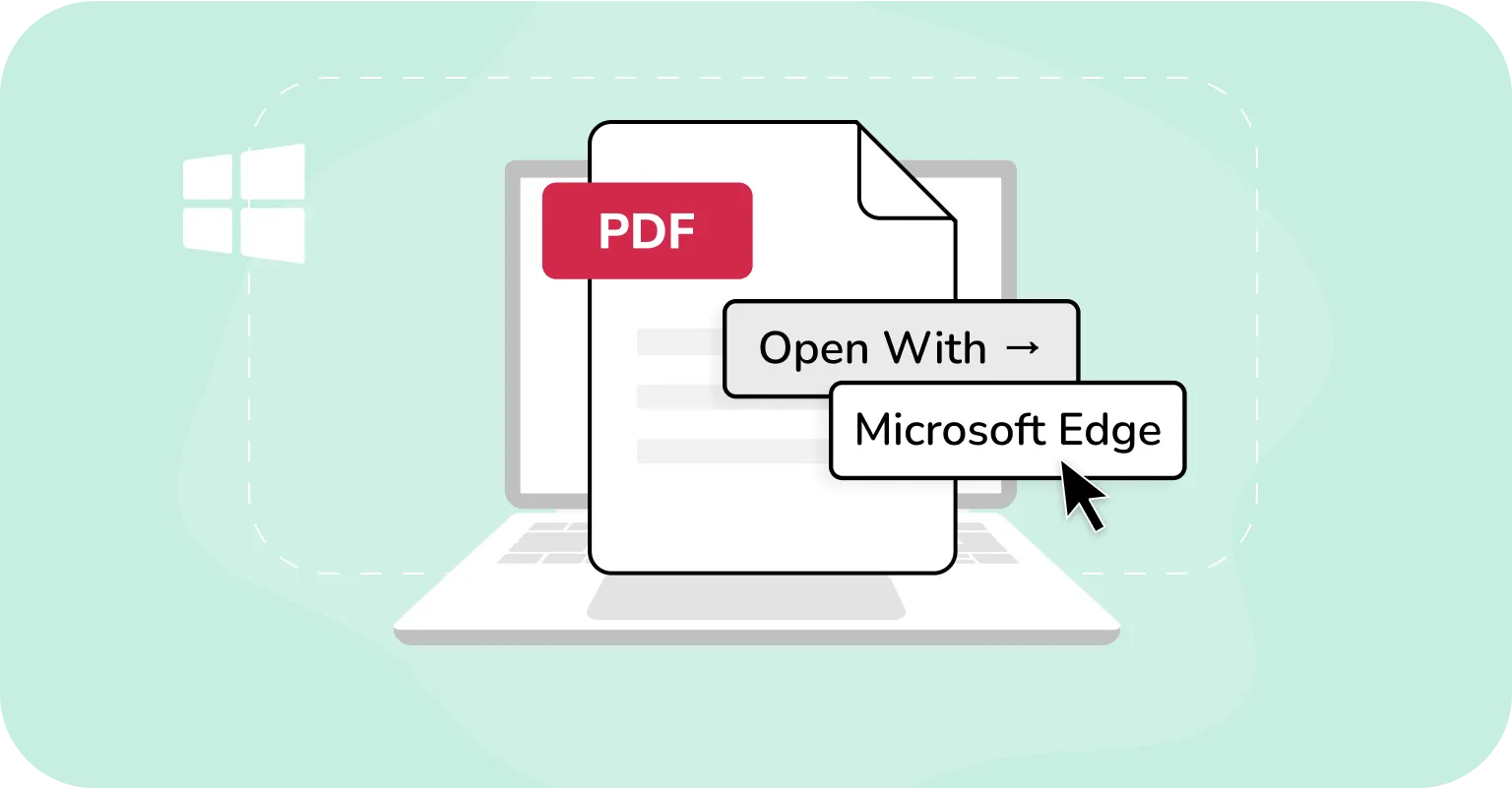
Op Windows:
- 1Open de PDF in Microsoft Edge.
- 2Als het bestand beveiligd is, toont Edge een melding zoals "Dit bestand heeft beperkte machtigingen. Mogelijk heb je geen toegang tot bepaalde functies", vaak met een koppeling "Machtigingen bekijken" onder de werkbalk.
- 3Klik op "Machtigingen bekijken" (indien beschikbaar) om meer te weten te komen over de beperkingen. Daarin staat bijvoorbeeld of je mag kopiëren, afdrukken of annoteren. Edge geeft echter geen volledig overzicht van alle machtigingsinstellingen.
- 4Als kopiëren beperkt is, mislukken pogingen om tekst te kopiëren uit PDF's die niet gekopieerd kunnen worden. Edge blokkeert de actie zonder melding.
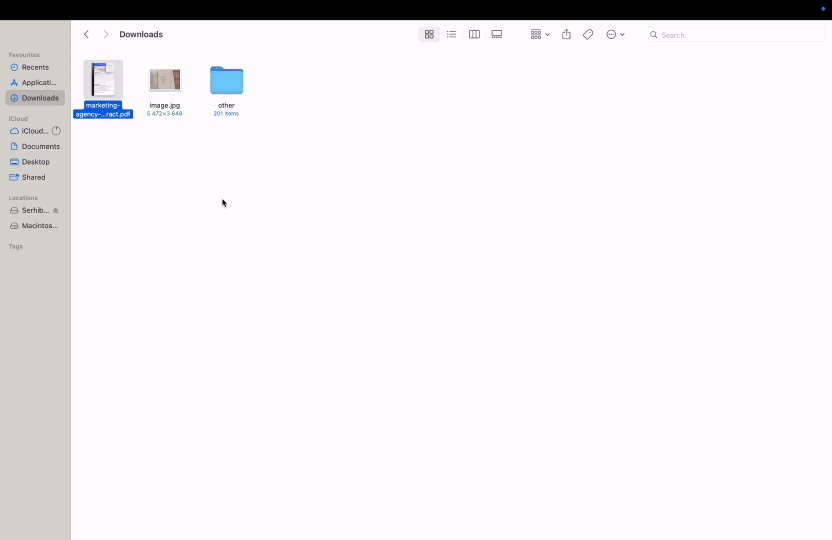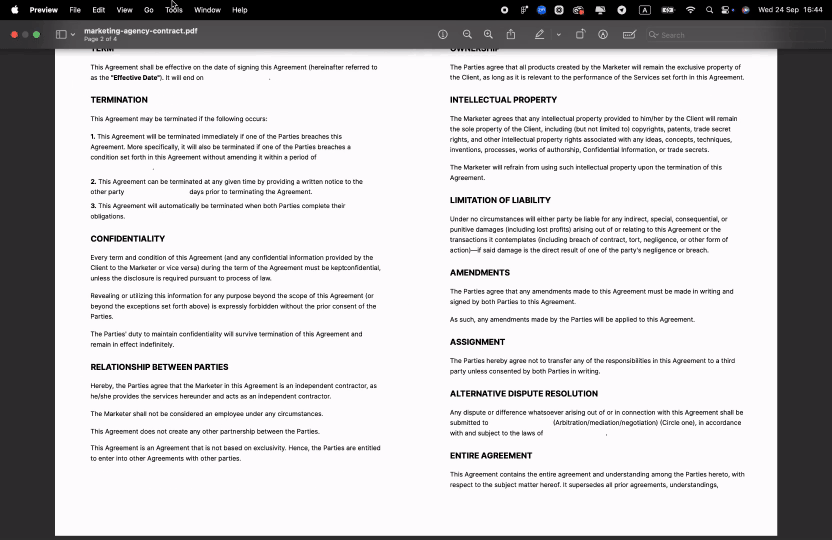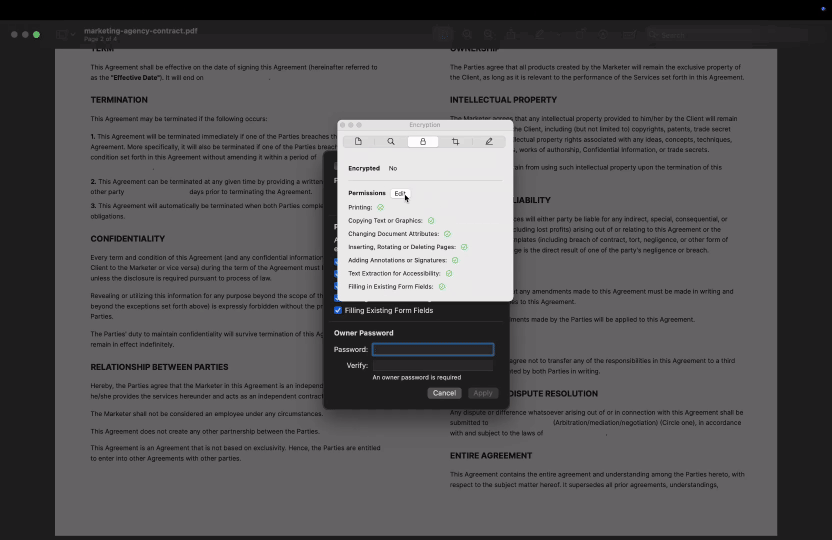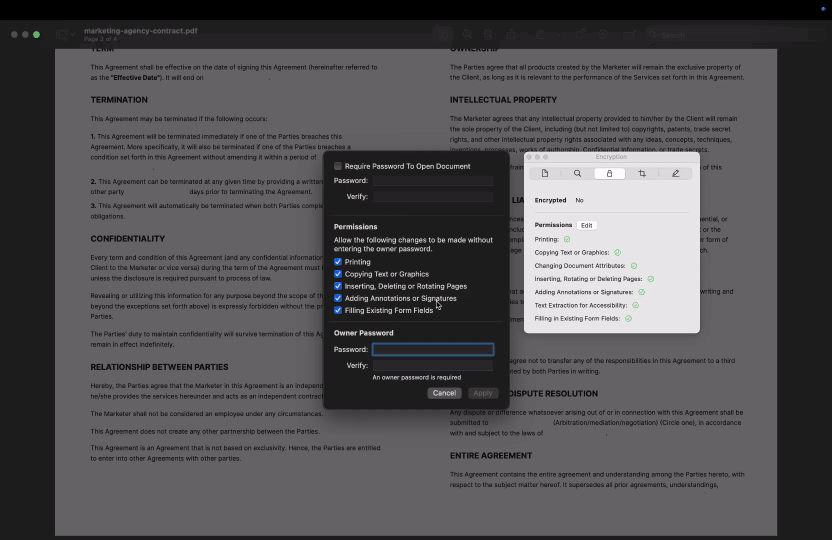
Op macOS:
- 1Open de PDF in Preview.
- 2Voor met een wachtwoord beveiligde PDF's kun je klikken op Hulpmiddelen > Toon Inspector en vervolgens het tabblad Encryption (Versleuteling) selecteren om te zien of bepaalde machtigingen, zoals kopiëren en plakken op Mac of afdrukken, beperkt zijn.
- 3Preview toont geen gedetailleerde machtigingsinformatie voor bestanden die niet met een wachtwoord beveiligd zijn. Als kopiëren beperkt is, blokkeert het programma het kopiëren van tekst zonder uitleg.
Wat te doen als de tekst in een PDF niet gekopieerd mag worden
Als kopiëren is beperkt maar je het wachtwoord kent, kun je het bestand ontgrendelen en die beperkingen opheffen. Dit soort wachtwoordbeveiliging is ook een veelvoorkomende reden waarom gebruikers PDF-bestanden niet kunnen bewerken, en dus niet alleen waarom ze er geen tekst uit kunnen kopiëren.
Tekst kopiëren uit een beveiligde PDF
Als je PDF kopieerbeperkingen heeft, voer dan het juiste wachtwoord in dat je van de eigenaar van het document hebt gekregen. Zodra het bestand ontgrendeld is, kun je de tekst selecteren en kopiëren.
Onze OCR-tool verwerkt geen met een wachtwoord beveiligde bestanden, omdat we privacy en de wettelijke bescherming rond versleutelde documenten respecteren. Als je zo'n bestand uploadt, krijg je de melding: "Het bestand is met een wachtwoord beveiligd. Ontgrendel het bestand en probeer het opnieuw." Dit betekent dat je het wachtwoord zelf moet verwijderen. Voer het in je PDF-lezer in of vraag de eigenaar van het bestand om een ontgrendelde kopie voordat je de conversie uitvoert.
Juridische en ethische opmerking: Kopieer alleen tekst wanneer je daar toestemming voor hebt of er wettelijk recht op hebt. Omzeil geen kopieerbeveiliging. Respecteer auteursrecht, licenties, contracten en privacyregels. Dit is algemene informatie en geen juridisch advies.
Tekst kopiëren uit een PDF-afbeelding
Als je PDF eigenlijk gewoon een afbeelding is, valt deze in dezelfde categorie als gescande PDF's: er is geen echte tekstlaag om uit te kopiëren. De oplossing is dezelfde — gebruik OCR om de tekst selecteerbaar te maken. Onze Afbeelding-naar-tekst-converter is gemaakt voor foto's en PDF's die alleen uit afbeeldingen bestaan. Hij scant de plaatjes en reconstrueert de tekens met behulp van AI, zodat je ze kunt selecteren, doorzoeken en hergebruiken.
Hoe haal je tekst uit een PDF-afbeelding met een OCR-tool
Gebruik onze OCR-afbeeldingsconverter om tekst uit een PDF-afbeelding te halen. Upload de gescande of op afbeeldingen gebaseerde PDF, start het OCR-proces en de tool zet de afbeelding om in machineleesbare tekst. Je kunt het resultaat vervolgens opslaan als doorzoekbare PDF om de lay-out te behouden, exporteren naar Word of Excel om te bewerken, of de platte tekst kopiëren voor snel hergebruik.
Hoe selecteer je tekst uit een PDF-afbeelding met Google Drive
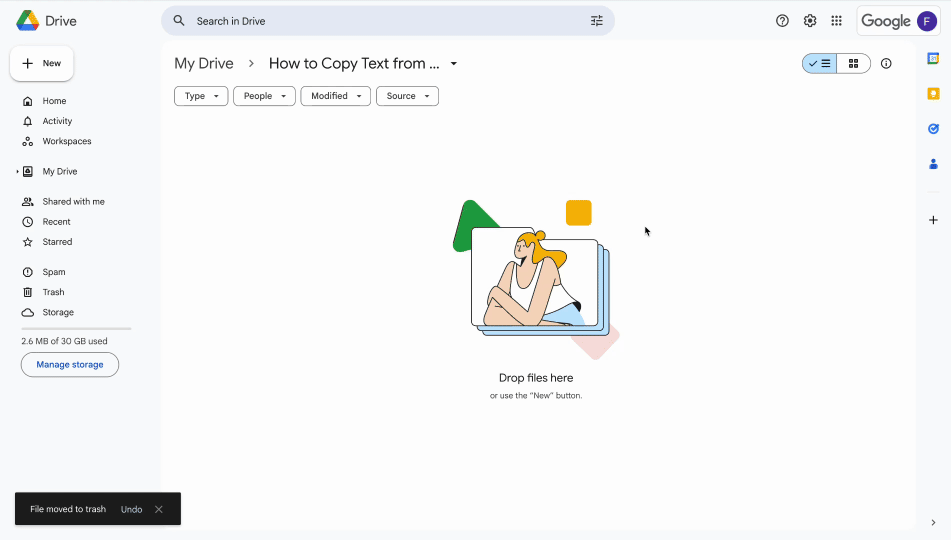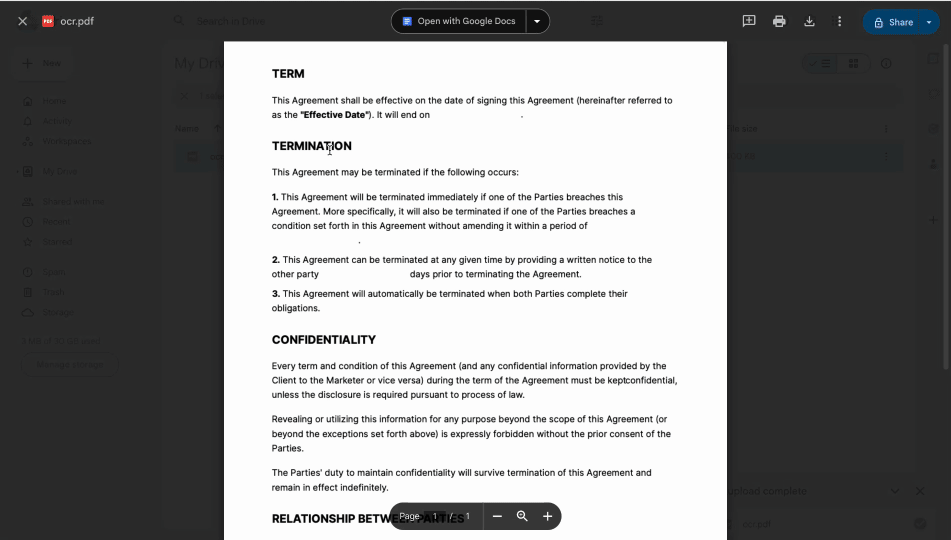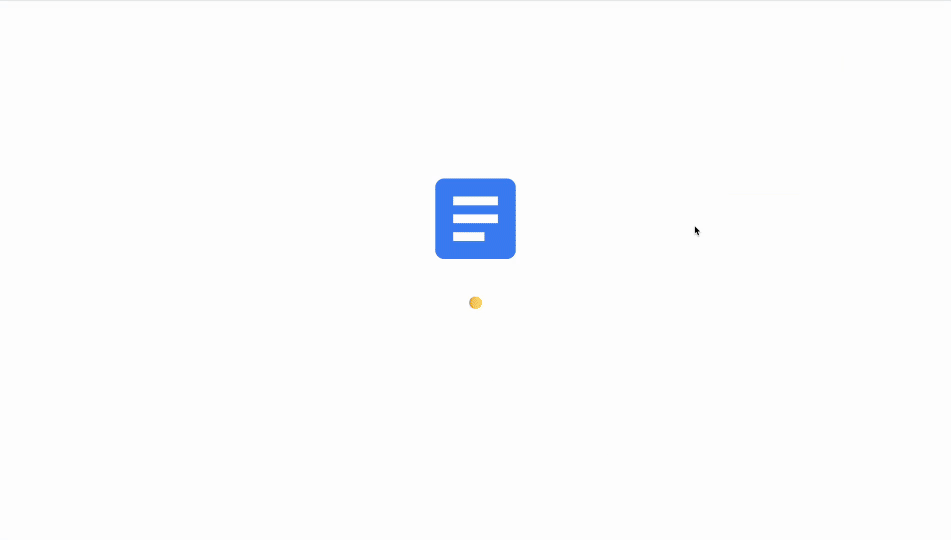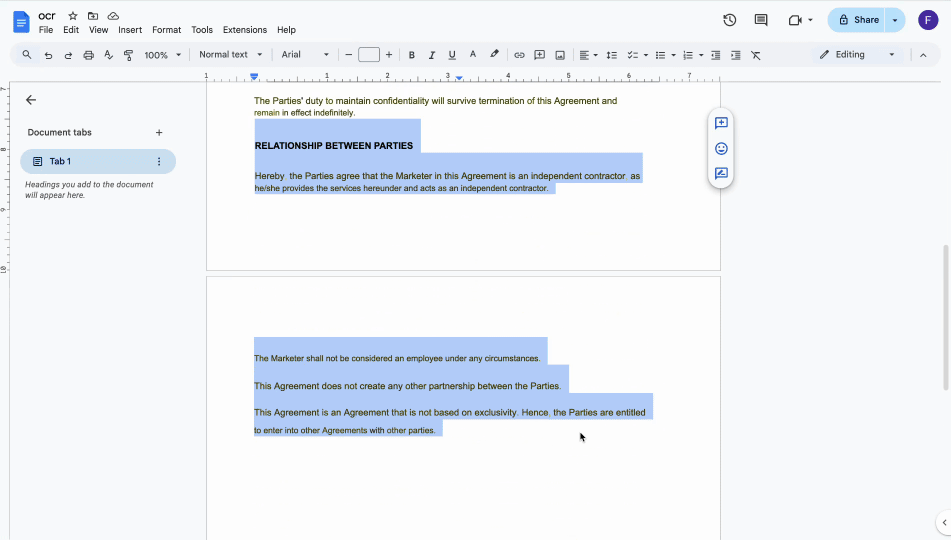
Om tekst uit PDF-afbeeldingen te kopiëren, kun je de ingebouwde OCR-functie van Google Drive gebruiken. Deze zet automatisch tekst uit afbeeldingen om in machineleesbare tekst die je eenvoudig kunt kopiëren en plakken op Mac of Windows. Zo werkt het:
- 1Open je Google Drive-account.
- 2Upload de PDF (Nieuw > Bestand uploaden of slepen en neerzetten).
- 3Klik met de rechtermuisknop op het geüploade bestand en kies Openen met > Google Docs.
Je PDF wordt in een nieuw tabblad geopend als een Google Docs-bestand. De voorheen niet-selecteerbare tekst wordt bewerkbaar en machineleesbaar, zodat je deze naar wens kunt kopiëren en plakken.
Let op: Een deel van de opmaak kan tijdens de conversie verloren gaan. Google Drive behoudt meestal vetgedrukte en cursieve stijlen, regeleinden en lettertypen, maar lijsten, tabellen, voetnoten en andere complexe elementen blijven niet altijd intact. Voor snellere en consistentere resultaten zonder opmaakproblemen kun je beter onze PDF-bewerktool proberen.
Tips voor de beste OCR-resultaten
OCR kan soms frustrerend zijn, want zelfs bij heldere scans kunnen kleine fouten optreden. Een letter "O" kan bijvoorbeeld worden gelezen als een nul, of "rn" als een "m". Zo verbeter je de nauwkeurigheid en pak je deze problemen aan:
- Zorg dat de tekst groot genoeg is (minstens 10–12 pixels hoog), zodat de tool tekens duidelijk kan herkennen.
- Houd de bestandsgrootte redelijk (minder dan ~100 MB voor webtools) om trage uploads of fouten te voorkomen.
- Controleer de oriëntatie. Draai ondersteboven of zijwaarts gerichte pagina's voordat je OCR uitvoert.
- Streef naar scherpe scans met veel contrast en eenvoudige, leesbare lettertypen zoals Arial of Times New Roman.
- Lees na OCR de tekst goed na om veelvoorkomende verkeerde herkenningen (zoals l/1, O/0, rn/m) op te sporen en te corrigeren.
- Blijven er fouten optreden, exporteer dan naar Word voor eenvoudiger bewerken of probeer een andere OCR-tool.
Deze tips gelden voor de meeste OCR-diensten, of ze nu geïntegreerd zijn in Google Drive, PDF Guru of vergelijkbare tools.
Verwerk scans slimmer met PDF Guru
Gescande of beveiligde PDF's hoeven je niet tegen te houden. Door OCR uit te voeren, kun je verborgen tekst zichtbaar maken, alle tekst uit PDF's kopiëren of pagina's omzetten in bewerkbare bestanden. Met de juiste AI-gestuurde tool worden zelfs vergrendelde documenten of bestanden die alleen uit afbeeldingen bestaan eenvoudig te gebruiken.


