
Nie wszystkie pliki PDF są takie same. Niektóre pozwalają swobodnie kopiować tekst, inne całkowicie to uniemożliwiają. Jeśli próby zaznaczenia i skopiowania tekstu nie działają, prawdopodobnie masz do czynienia z zeskanowanym dokumentem lub takim, w którym włączono ograniczenia kopiowania.
Dobra wiadomość jest taka, że istnieje kilka skutecznych metod kopiowania tekstu ze zeskanowanego pliku PDF, nawet jeśli jest zablokowany lub zawiera zeskanowane strony zamiast edytowalnego tekstu. W tym poradniku przeprowadzimy Cię przez różne rozwiązania, abyś mógł swobodnie uzyskać dostęp do tekstu w swoich plikach PDF, ponownie go wykorzystać i przystosować do własnych potrzeb.
Czy można skopiować tekst z pliku PDF?
Tak, w większości przypadków możesz skopiować treść z pliku PDF, który zawiera cyfrowo osadzony tekst, a nie zeskanowane obrazy. Cyfrowo osadzony tekst to znaki przechowywane jako rzeczywiste dane tekstowe, a nie jako część obrazu, dzięki czemu możesz zaznaczać oraz używać poleceń kopiuj i wklej w treści przy użyciu standardowych skrótów.
Oto jak skopiować tekst ze standardowego pliku PDF:
- 1Otwórz plik PDF w dowolnej przeglądarce PDF na swoim urządzeniu (np. Microsoft Edge w systemie Windows lub Preview na komputerze Mac).
- 2Zaznacz potrzebny tekst (lub naciśnij Ctrl+A (w systemie Windows) albo Cmd+A (w macOS), aby zaznaczyć wszystko).
- 3Naciśnij Ctrl+C/Cmd+C, aby skopiować.
- 4Otwórz lub utwórz dokument docelowy, w którym chcesz wstawić tekst.
- 5Naciśnij Ctrl+V/Cmd+V, aby wkleić tekst.
Jeśli wszystko zadziała, skopiowana treść powinna znajdować się w schowku, gotowa do wklejenia do dowolnego dokumentu lub aplikacji, w tym do edytorów takich jak Word czy Excel.
Jak skopiować tekst z PDF za pomocą narzędzia OCR od PDF Guru
Jeśli Twój plik PDF to skan lub dokument zawierający tylko obrazy, nie skopiujesz tekstu bezpośrednio, ponieważ nie jest on przechowywany jako tekst możliwy do zaznaczenia. Aby uzyskać dostęp do treści, musisz zastosować optyczne rozpoznawanie znaków (OCR), wspierane przez technologię AI, które analizuje obraz i zamienia go w tekst, który można zaznaczać, przeszukiwać i edytować.
Oto jak skorzystać z konwertera OCR PDF od PDF Guru, aby wyodrębnić tekst w PDF lub na obrazie:
- 1Prześlij plik lub przeciągnij go i upuść.
- 2
Wybierz format wyjściowy: przeszukiwalny PDF, dokument Word lub zwykły tekst.
- Przeszukiwalne pliki PDF zachowują układ i wygląd.
- Word jest najlepszy do dalszej edycji.
- Zwykły tekst daje Ci wyłącznie surową treść bez żadnego formatowania.
- 3
Kliknij Pobierz i zaczekaj, aż nasz system przetworzy plik.
Chcesz od razu przejść do edycji? Wypróbuj nasz konwerter PDF do Word.

Jak sprawdzić, czy plik PDF pozwala na kopiowanie tekstu?
Jeśli nie możesz wykonać operacji kopiuj i wklej z PDF, zazwyczaj sprowadza się to do jednej z dwóch kwestii: plik został zeskanowany (tzn. tekst jest częścią obrazu) lub ma ograniczenia bezpieczeństwa uniemożliwiające kopiowanie. Oto jak ustalić źródło problemu.
Krok 1: Spróbuj zaznaczyć tekst
Jeśli nie możesz zaznaczyć żadnego tekstu w swoim dokumencie PDF, prawdopodobnie zawiera on zeskanowane obrazy. W takim przypadku wypróbuj nasz konwerter PDF na OCR, który przekształca skany w przeszukiwalne i edytowalne pliki. Wyjaśnimy, jak to działa, w następnej sekcji.
Jeśli możesz zaznaczać tekst w plikach PDF, ale nic się nie dzieje po jego skopiowaniu, oznacza to, że plik ma ograniczenia bezpieczeństwa.
Krok 2: Sprawdź uprawnienia dokumentu
Możesz potwierdzić, czy Twój plik pozwala na kopiowanie, sprawdzając jego ustawienia zabezpieczeń w domyślnej przeglądarce PDF:
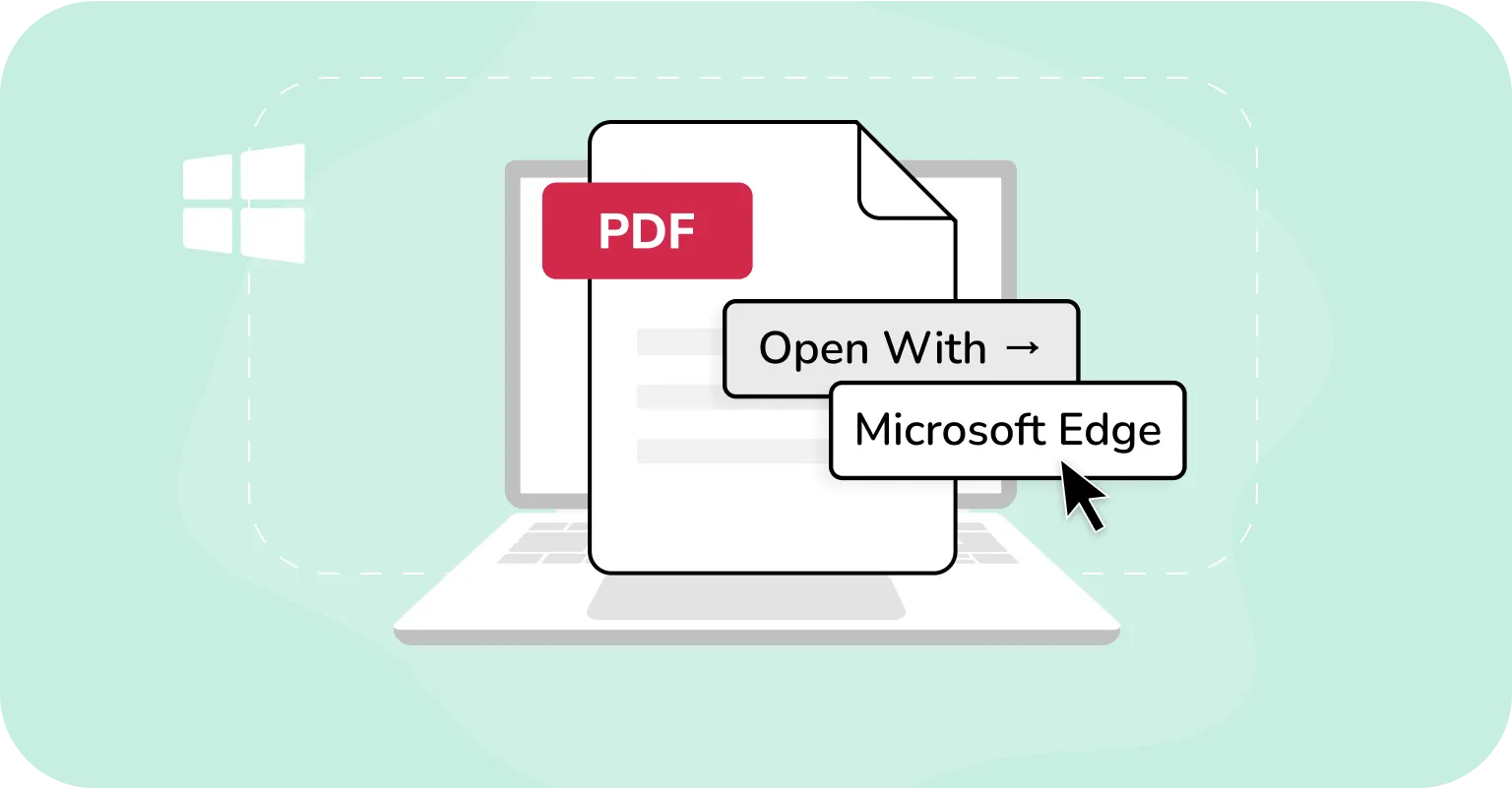
W systemie Windows:
- 1Otwórz plik PDF w Microsoft Edge.
- 2Jeśli plik jest chroniony, Edge wyświetli komunikat w stylu „Ten plik ma ograniczone uprawnienia. Możesz nie mieć dostępu do niektórych funkcji”, często z linkiem „Wyświetl uprawnienia” pod paskiem narzędzi.
- 3Kliknij „Wyświetl uprawnienia” (jeśli dostępne), aby dowiedzieć się o ograniczeniach. Mogą one obejmować to, czy możesz kopiować, drukować lub komentować. Edge nie zapewnia jednak pełnego zestawienia wszystkich ustawień uprawnień.
- 4Jeśli kopiowanie jest ograniczone, próby skopiowania tekstu z plików PDF, których nie można skopiować, zakończą się niepowodzeniem. Edge po cichu zablokuje to działanie.
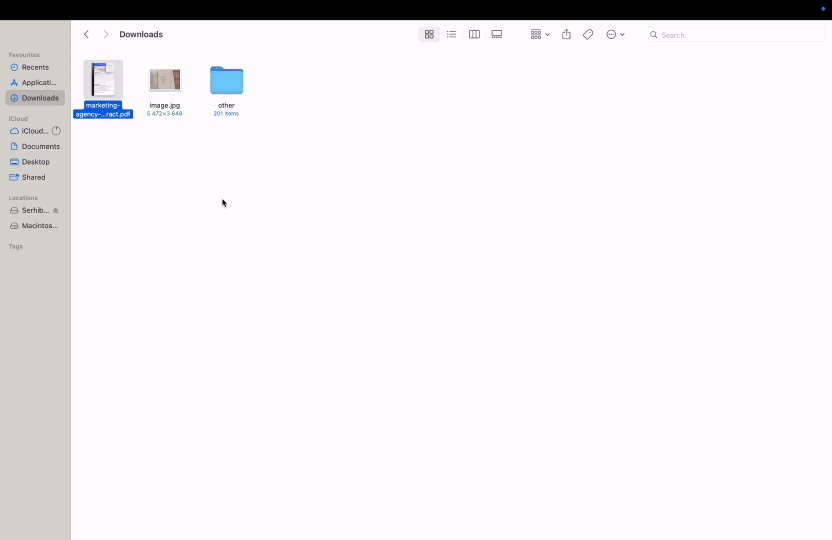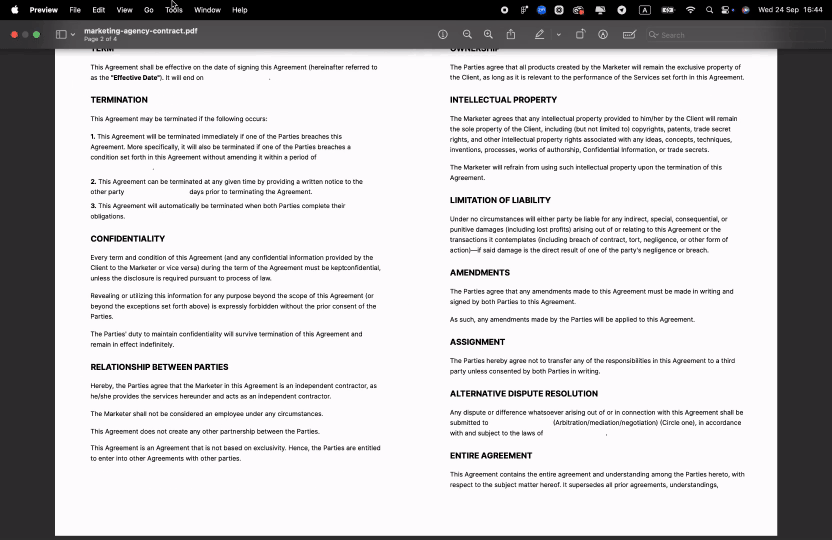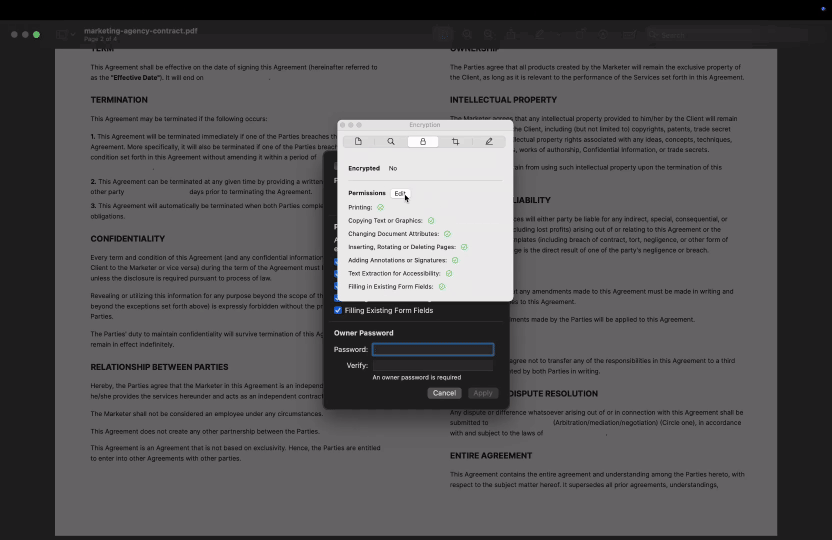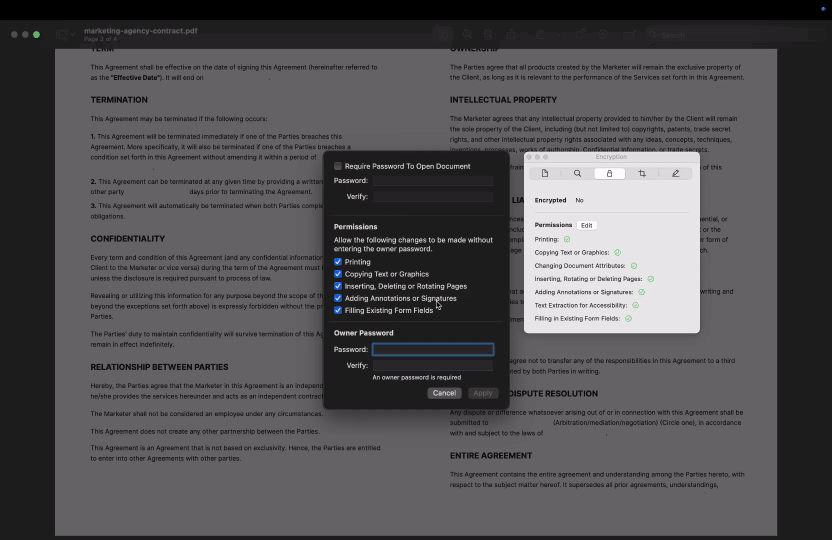
W systemie macOS:
- 1Otwórz plik PDF w aplikacji Preview.
- 2W przypadku plików PDF chronionych hasłem możesz kliknąć Narzędzia > Pokaż inspektora, a następnie wybrać zakładkę Szyfrowanie, aby zobaczyć, czy jakieś uprawnienia są ograniczone, np. kopiowanie lub drukowanie.
- 3Preview nie wyświetla szczegółowych informacji o uprawnieniach dla plików niezabezpieczonych hasłem. Jeśli kopiowanie jest ograniczone, program zablokuje kopiowanie tekstu bez wyjaśnienia.
Co zrobić, gdy kopiowanie tekstu z PDF jest ograniczone
Jeśli kopiowanie tekstu jest ograniczone, ale znasz hasło, możesz odblokować plik i znieść te ograniczenia. Ten rodzaj ochrony hasłem to także częsty powód, dla którego użytkownicy nie mogą edytować plików PDF, a nie tylko z nich kopiować.
Jak skopiować tekst z chronionego pliku PDF
Jeśli Twój plik PDF ma ograniczenia kopiowania, wprowadź prawidłowe hasło od właściciela dokumentu. Po odblokowaniu pliku możesz zaznaczyć i skopiować tekst.
Nasze narzędzie OCR nie przetwarza plików chronionych hasłem, ponieważ szanujemy prywatność i ochronę prawną dokumentów zaszyfrowanych. Jeśli prześlesz taki plik, zobaczysz komunikat: „Plik jest chroniony hasłem. Odblokuj plik i spróbuj ponownie”. Oznacza to, że musisz sam usunąć hasło. Po prostu wprowadź je w swojej przeglądarce PDF lub poproś właściciela pliku o wersję bez zabezpieczeń, zanim uruchomisz konwersję.
Uwaga prawna i etyczna: Kopiuj tekst tylko wtedy, gdy masz zgodę lub prawo do tego. Nie omijaj zabezpieczeń przed kopiowaniem. Szanuj prawa autorskie, licencje, umowy i zasady prywatności. To informacja ogólna, a nie porada prawna.
Jak skopiować tekst z obrazu PDF
Jeśli Twój plik PDF to tylko obraz, należy do tej samej kategorii co zeskanowane pliki PDF: nie ma w nim prawdziwej warstwy tekstu, którą można by skopiować. Rozwiązanie jest takie samo — użyj OCR, aby tekst stał się możliwy do zaznaczenia i w pełni edytowalny. Nasz konwerter Obraz na Tekst został stworzony dla zdjęć i plików PDF zawierających tylko obrazy, skanując ilustracje i odtwarzając znaki, dzięki czemu możesz je zaznaczać, wyszukiwać i wykorzystywać ponownie.
Jak wyodrębnić tekst z obrazu PDF za pomocą narzędzia OCR
Aby wyodrębnić tekst z obrazu PDF, użyj naszego konwertera OCR dla obrazów wykorzystującego AI. Prześlij zeskanowany lub bazujący na obrazach plik PDF, uruchom proces OCR, a narzędzie zamieni obraz w tekst odczytywalny maszynowo. Następnie możesz zapisać wynik jako przeszukiwalny PDF, aby zachować układ, wyeksportować do Word w celu edycji lub skopiować zwykły tekst do szybkiego ponownego użycia.
Jak zaznaczyć tekst z obrazu PDF za pomocą Google Drive
Aby skopiować tekst z obrazów PDF, możesz skorzystać z wbudowanej funkcji OCR w Google Drive. Automatycznie konwertuje ona tekst z obrazu na tekst odczytywalny maszynowo, który można łatwo skopiować. Oto jak to działa:
- 1Otwórz swoje konto Google Drive.
- 2Prześlij plik PDF (Nowy > Prześlij plik lub przeciągnij i upuść).
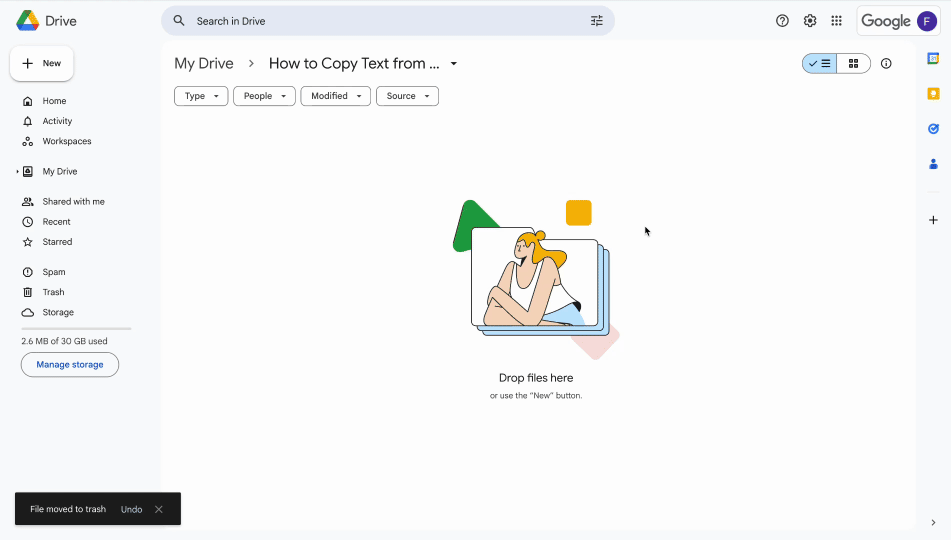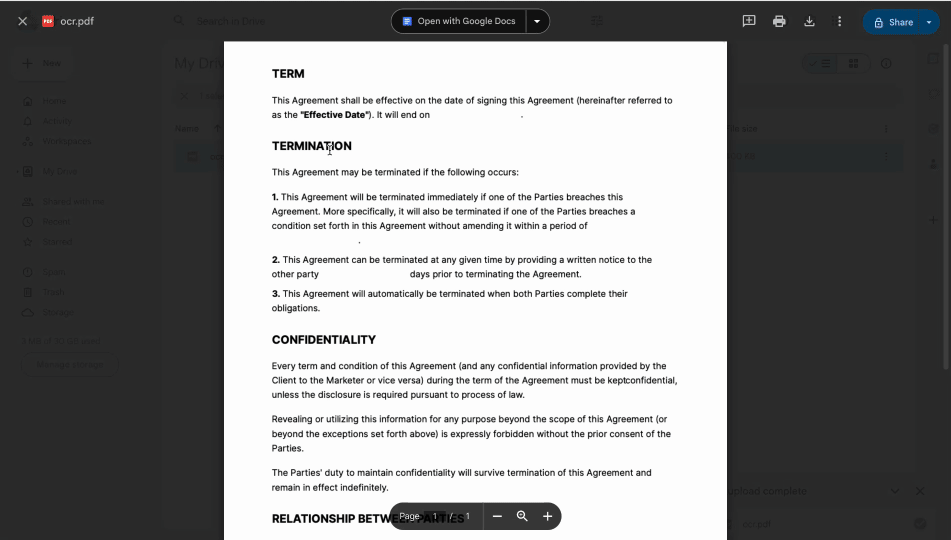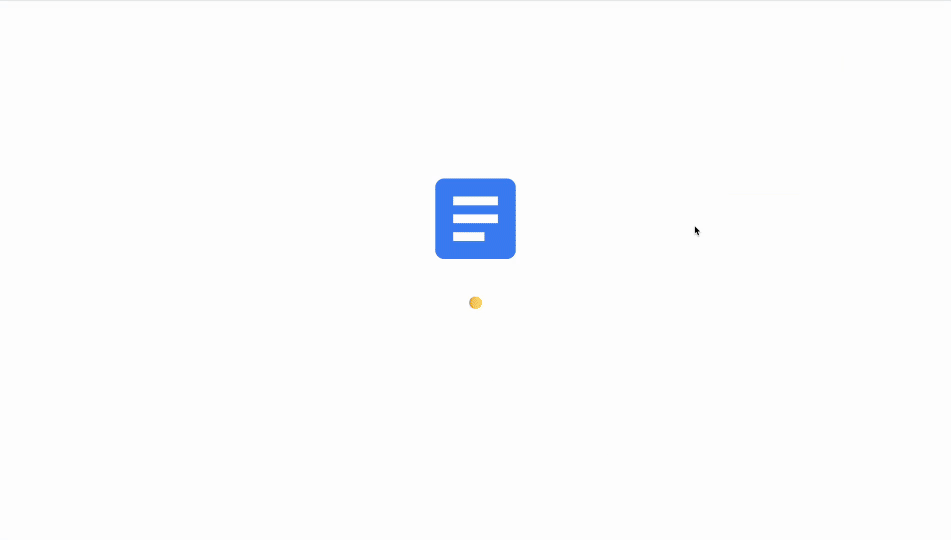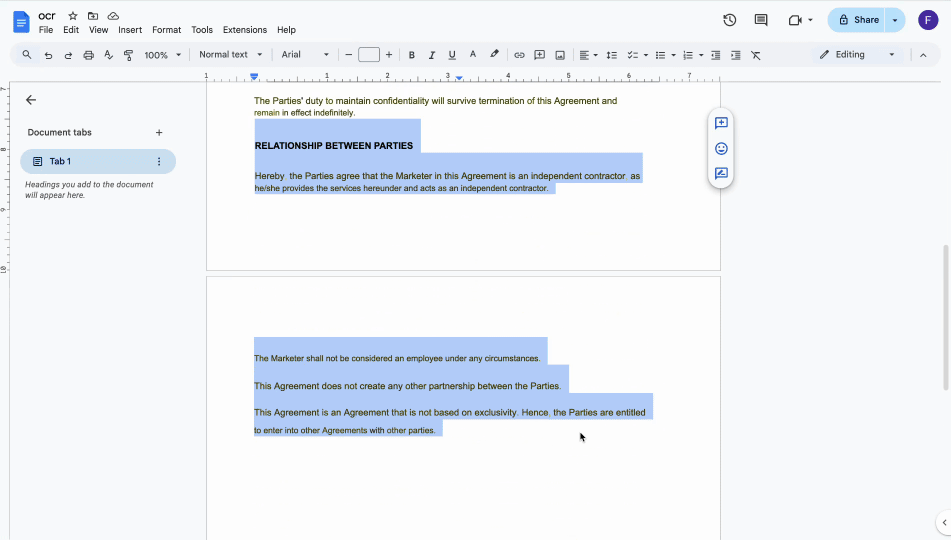
- 3Kliknij prawym przyciskiem myszy przesłany plik i wybierz Otwórz za pomocą > Google Docs.
Twój plik PDF otworzy się w nowej karcie jako dokument Google Docs. Wcześniej nieedytowalny tekst stanie się edytowalny i odczytywalny maszynowo, co pozwoli Ci go skopiować i wkleić w razie potrzeby.
Uwaga: Niektóre elementy formatowania mogą zostać utracone podczas konwersji. Chociaż Google Drive zazwyczaj zachowuje style pogrubienia i kursywy, podziały wierszy oraz czcionki, może nie zachować list, tabel, przypisów ani innych złożonych elementów. Aby uzyskać szybsze i bardziej spójne rezultaty bez problemów z formatowaniem, wypróbuj zamiast tego nasze narzędzie do edycji PDF.
Wskazówki dotyczące najlepszych wyników OCR
OCR potrafi czasem frustrować, ponieważ nawet przy wyraźnych skanach mogą pojawić się drobne błędy. Na przykład litera „O” może zostać odczytana jako zero lub „rn” jako „m”. Oto jak poprawić dokładność i radzić sobie z tymi problemami:
- Upewnij się, że tekst jest wystarczająco duży (co najmniej 10–12 pikseli wysokości), aby narzędzie mogło wyraźnie rozpoznać znaki.
- Utrzymuj rozsądny rozmiar pliku (poniżej ~100 MB w przypadku narzędzi internetowych), aby uniknąć powolnych przesyłań lub błędów.
- Sprawdź orientację. Obróć strony do góry nogami lub bokiem przed uruchomieniem OCR.
- Dąż do ostrych, kontrastowych skanów z prostymi, czytelnymi czcionkami, takimi jak Arial lub Times New Roman.
- Sprawdź tekst po OCR, aby wychwycić i poprawić typowe błędy (np. l/1, O/0, rn/m).
- Jeśli błędy się utrzymują, wyeksportuj do Word, by ułatwić edycję, lub spróbuj innego narzędzia OCR opartego na AI.
Te praktyki sprawdzają się w większości usług OCR, niezależnie od tego, czy są zintegrowane z Google Drive, PDF Guru, czy innymi podobnymi narzędziami.
Obsługuj skany mądrzej dzięki PDF Guru
Zeskanowane lub chronione pliki PDF nie muszą Cię ograniczać. Uruchamiając OCR, możesz odsłonić ukryty tekst w PDF, skopiować całą zawartość plików PDF lub zamienić strony w pliki edytowalne. Z odpowiednim narzędziem nawet zablokowane lub złożone z samych obrazów dokumenty stają się łatwe w obsłudze.


